Международный Институт Профессионального Образования
Дополнительное образование для специалистов нефтегазовой отрасли
Международный Институт Профессионального Образования
Дополнительное образование для специалистов нефтегазовой отрасли
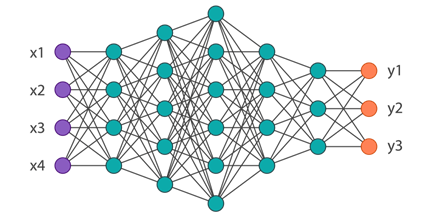 Рисунок 1. Архитектура полносвязной нейронной сети
Рисунок 1. Архитектура полносвязной нейронной сети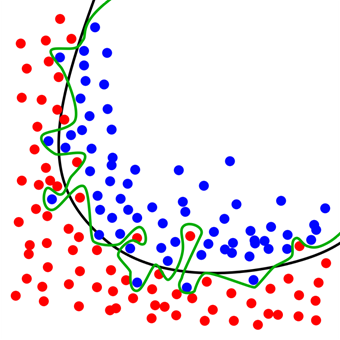 Рисунок 2. Проблема переобучения нейронной сети
Рисунок 2. Проблема переобучения нейронной сети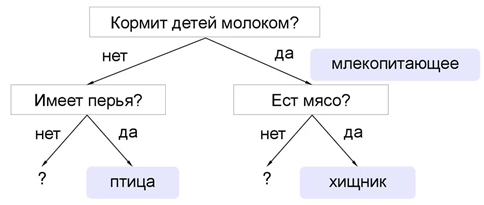 Рисунок 3. Пример принципа работы алгоритма Random Forest
Рисунок 3. Пример принципа работы алгоритма Random Forest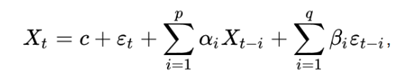 Формула 1. Модель ARMA (Авторегрессии скользящего среднего)
Формула 1. Модель ARMA (Авторегрессии скользящего среднего)